

Last week, while working on a new landing page element with Headout, the project manager (PM) asked me a fundamental question:
How will we know if this is a success from an organic POV?
Initially, I almost blurted out, ‘Better rankings, more clicks, blah blah blah,’ but I knew that wasn’t a given—especially in today’s landscape. After thinking more about tangible versus intangible outcomes, I paused and said, ‘Increase in crawl rate.’
In typical fashion, the PM’s next question was, ‘By how much?‘
That’s when I was stumped. I asked for more time.
I went down a rabbit hole, and now, I hope to share those insights here in a distilled manner. It turns out there’s a mathematical basis for this concept: the Poisson Process Model (a way to predict how often something changes).”
We consider a Poisson process model for the number of state changes of a page, where a crawler samples the page at some known (but variable) time interval and observes whether or not the page has changed in during that interval.
– Proceedings of INTERFACE 2008
How did I end up here?
My first thought was to ask ChatGPT, “If I change 20% of my page content, how much more will Googlebot crawl my content?” The answer was unsatisfactory. I could sense the “yes” bias of the LLM. I turned to research and patent papers where I came across this paper from 2008 from Carrie Grimes, Daniel Ford and Eric Tassone; Proceedings of INTERFACE 2008
A brief about these personalities
Carrie Grimes graduated from Stanford in 2003 with a PhD in Statistics after working with David Donoho on Nonlinear Dimensionality Reduction problems, and has been at Google since mid-2003. Dr. Grimes spent many years leading a research and technical team in Search at Google trying to figure out what criteria make a search engine index “good,” “fast,” and “comprehensive” – and how to achieve those goals.
This is from Daniel’s Linkedin
Designed, implemented and drove adoption of quality metrics and monitoring for webpage crawl scheduling and index selection algorithms, the core of Google’s search engines, improving freshness 50% and quality of web internal and user-facing metrics.
Eric is now back at Google after a brief stint in academia. Here’s a snippet from his LinkedIn
Search Infrastructure, 2007–2012: Manager and TL. Coordinated index strategy and policy. Built tools for principled quantitative decision-making about content discovery, indexing, and refresh, leading to substantial resource conservation. Co-inventor on patent application US20130212100A1 for “Estimating rate of change of documents.” Liaison to public policy and legal teams.
Why is it important to keep a search engine fresh?
Search engines crawl the web to download a corpus of web pages to index for user queries. Since websites update all the time, the process of indexing new or updated pages requires continual refreshing of the crawled content. In order to provide useful results for time-sensitive or new-content queries, a search engine would ideally maintain a perfectly up-to-date and comprehensive copy of the web at all times. This goal requires that a search engine acquire new links as they appear and refresh any new content that appears on existing pages.
As the web grows to many billions of documents and search engine indexes scale similarly, the cost of re-crawling every document all the time becomes increasingly high. One of the most efficient ways to maintain an up-to-date corpus of web pages for a search engine to index is to crawl pages preferentially based on their rate of content update
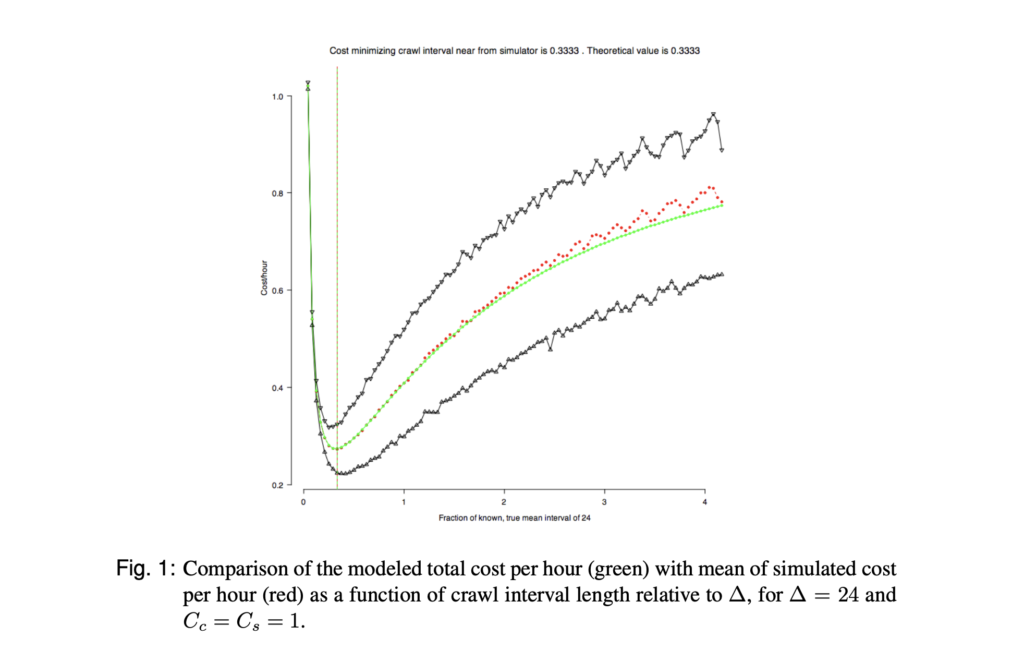
Summary from the PDF
The calculations in the PDF aim to find the optimal time interval for web page crawling by balancing two competing costs: the cost of crawling the page too often Cc and the cost of having stale content Cs(i.e., not crawling the page often enough when the content changes). Mathematically
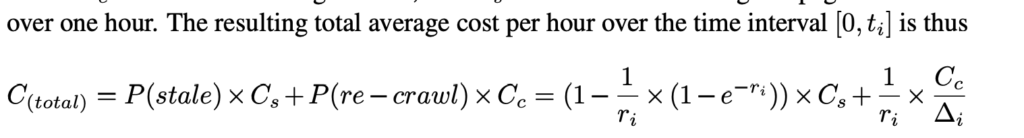
The model focuses on estimating when web pages change and determines how often they should be re-crawled. This ties directly into your query about content significance: frequent or large changes would increase the probability of re-crawling, while minimal or superficial changes might not trigger as frequent crawls.
Key Ideas in the PDF:
- Poisson Process for Changes: The Poisson process estimates how frequently a web page’s content changes. If a page updates more frequently (higher λ), the crawler should visit more often. If changes happen rarely, crawling can be less frequent.
- Total Cost: The document describes how to minimize the total cost, which includes:
- Crawl Cost (Cc): The cost of each crawl (time, resources, bandwidth).
- Staleness Cost (Cs): The cost of a page being outdated when users view it.
- Optimal Crawl Interval: The goal is to calculate how frequently to crawl a page (denoted as ti) based on how often the content changes (denoted as λ) to minimize the total cost. If a page changes often, you reduce the interval (crawl more frequently).

Are there any metrics in the leak?
Here are all the metrics I could find and then I asked the o1 model to try to bridge them up.
- urlChangerate
- urlHistory
- components
- logScaling
- type
- weight
- additionalChangesMerged
- fractionalTileChange
- interval
- offDomainLinksChange
- offDomainLinksCount
- onDomainLinksCount
- onDomainLinksCountChange
- shingleSimhash
- simhash
- simhashIsTrusted
- simhashV2
- simhashV2IsTrusted
- approximatedPosterior
- averageChangeSignificance
- changeperiod
- confidence
- globalBasedChangePeriod
- globalBasedChangePeriodConfidence
- globalBasedPriorPeriod
- globalBasedPriorStrength
- lastChangeSignificance
- lastChanged
- lastFetched
- numIntervals
- patternBasedChangePeriod
- patternBasedChangePeriodConfidence
- patternBasedLowerChangePeriod
- patternBasedPriorPeriod
- patternBasedPriorStrength
- patternChangePeriodVersion
- type
- ugcChangePeriod
- ugcChangePeriodConfidence
- change
- latestVersion
- url
- additionalChangesMerged
- contentType
- isImsNotModified
- lastModified
- shingleSimhash
- simhash
- simhashIsTrusted
- simhashV2
- simhashV2IsTrusted
- timestamp
You can access the complete documentation with the description and module info below.
Shoutout to Dixon Jones, for making the tabular doc on Google leak. Much easier to consume
We made reasonable assumptions basis the descriptions of these factors to come up with the following link up:
1. Timestamp and Last-Modified Headers
HTTP Last-Modified Header:
- Definition: This is an HTTP response header that indicates the date and time at which the origin server believes the resource was last modified.
- Role in Crawling:
- Change Detection: Search engines use the
Last-Modifiedheader to determine if a page has been updated since the last crawl. - Crawl Scheduling: If the header shows a recent modification, the crawler may prioritize re-crawling that page sooner.
- Change Detection: Search engines use the
Correlation with Poisson Process:
- Enhancing λ Estimation: The Poisson process relies on estimating the rate of change (λ). Accurate
Last-Modifiedtimestamps provide empirical data that improve the estimation of λ, leading to more efficient crawl scheduling. - Reducing Uncertainty: Reliable timestamps decrease the uncertainty in predicting content changes, allowing for better optimization between crawl cost and freshness.
2. Content-Type
Definition:
- Specifies the media type of the resource (e.g.,
text/html,application/json,image/png).
Impact on Crawling:
- Change Frequency Variance: Different content types tend to have different update frequencies. For example:
- Text/HTML Pages: Often change more frequently, especially blogs or news sites.
- Images and Media Files: Generally change less often.
- Crawl Prioritization: Knowing the content type helps crawlers prioritize resources that are more likely to change.
Relation to Poisson Process:
- Content-Specific λ Values: By categorizing pages based on content type, search engines can assign different λ values, refining the Poisson model for each content category.
- Optimized Resource Allocation: This ensures that resources are allocated efficiently, crawling pages that change more often with appropriate frequency.
3. Bridging the Factors
Integrating Timestamps and Content-Type into Crawling Strategies:
- Data-Driven Estimation: Timestamps and content types provide concrete data points that feed into the Poisson process model, enhancing the accuracy of change rate estimations.
- Dynamic Crawl Scheduling:
- Adaptive Intervals: By continuously updating λ with new timestamp data, crawl intervals can be adjusted dynamically to match the observed change frequency.
- Cost Optimization: This minimizes the total cost by balancing the cost of crawling (
Cc) and the cost of staleness (Cs), as discussed in the PDF.
Practical Example:
- Scenario: A news website updates its homepage (
text/html) multiple times a day, indicated by frequent changes in theLast-Modifiedheader. - Crawler Response:
- Higher λ: The crawler assigns a higher λ to this page due to the observed update frequency.
- Shorter Crawl Interval: According to the Poisson model, the optimal crawl interval (
ti) decreases, prompting more frequent crawls to keep content fresh.
4. Additional Factors Search Engines Consider
Content Freshness Signals:
- Sitemaps with Timestamps: Webmasters can submit sitemaps that include tags, providing hints to crawlers about which pages have changed.
- Change Frequency Metadata: Although less common now, some sitemaps include tags to indicate how often a page is likely to change.
Quality and Relevance Signals:
- User Engagement Metrics: High bounce rates or low dwell times might signal outdated or less relevant content.
- Inbound Links and Social Signals: Increased linking to a page can indicate fresh or trending content, influencing crawl frequency.
5. Practical Implications for Webmasters
Ensuring Accurate Timestamps:
- Server Configuration: Make sure your web server correctly implements and updates the
Last-Modifiedheader when content changes. - Avoiding Misleading Headers: Incorrect timestamps can lead to inefficient crawling—either too frequent (wasting resources) or too infrequent (serving stale content).
Content Management:
- Regular Updates: Consistently updating significant portions of your content can increase λ, prompting search engines to crawl your site more often.
- UGC Management: Actively moderated user-generated content can contribute to content freshness without compromising quality.
6. Balancing Crawl Costs and Content Freshness
As outlined in the PDF, there’s a trade-off between the cost of crawling (Cc) and the cost of serving stale content (Cs). Incorporating factors like timestamps and content types into the Poisson process model helps search engines optimize this balance:
- Minimizing Total Cost: By accurately estimating λ using additional factors, search engines can set crawl intervals that minimize the combined cost of crawling and staleness.
- Risk Management: Better estimations reduce the risk of content becoming excessively stale, improving user satisfaction.
Summary
- Integration of Factors: Timestamps (
Last-Modified), content types, and observed content changes all feed into the estimation of the page change rate (λ) in the Poisson process model. - Enhanced Crawling Efficiency: These factors help search engines make informed decisions about crawl scheduling, ensuring fresh content is indexed promptly while conserving resources.
- Actionable Steps: By providing accurate metadata and regularly updating significant content, webmasters can positively influence crawl frequency and indexing.
What’s next?
As for Headout, we’re still a couple of months away from rolling out new elements. In the meantime, we’ve been establishing our baseline metrics. Next, we’ll launch experiments to measure how different percentages of page changes, at various frequencies, impact crawl rates.
We’re keeping a caveat in mind: if the current crawl rate is already higher than the rate of significant content changes, we may not see a further increase in crawl frequency. However, this could impact organic visibility, even if crawl frequency remains the same.